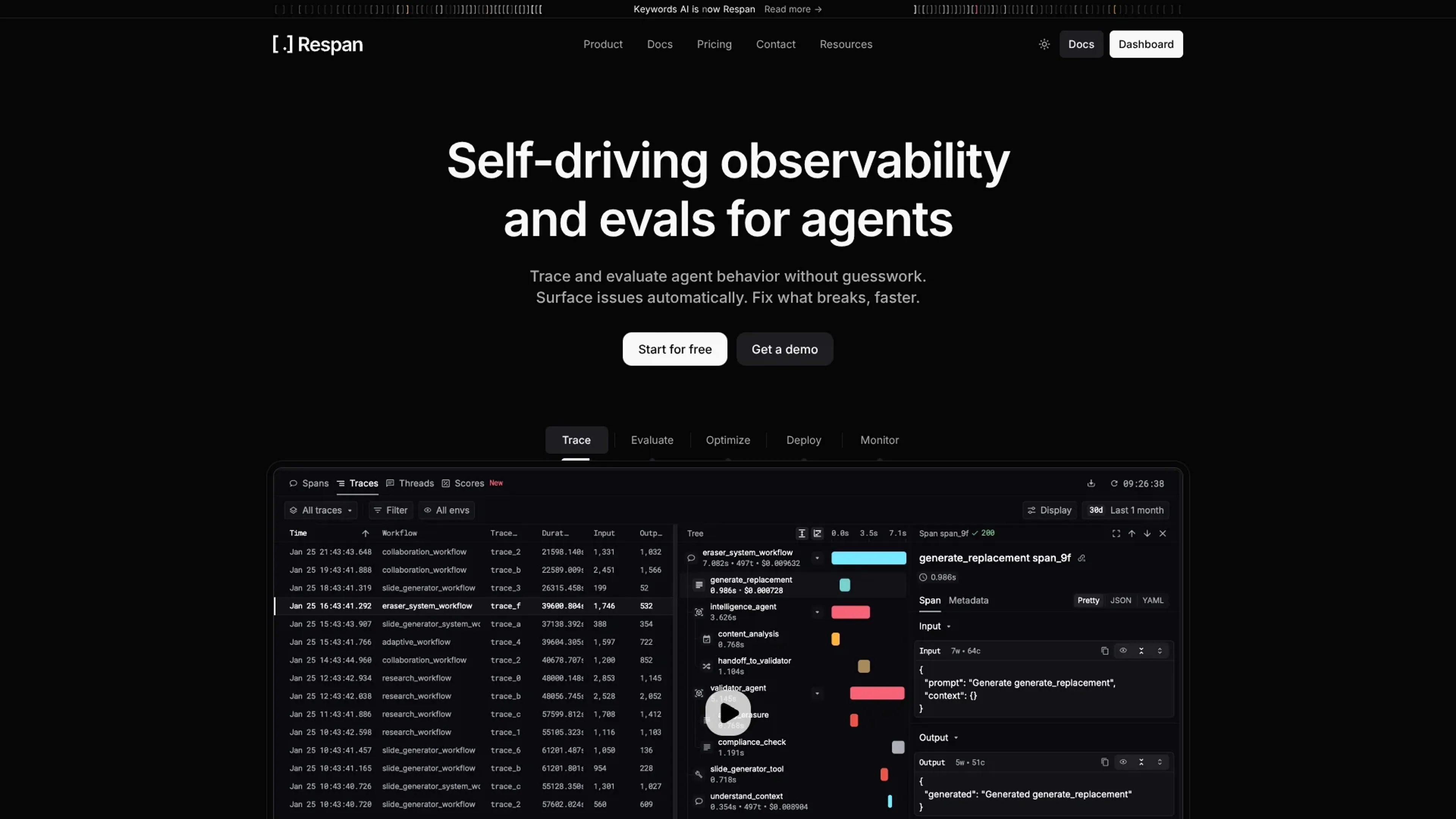
Respan focuses on LLM engineering, giving teams a central gateway and tracing layer for AI applications. It routes traffic to providers such as OpenAI, Anthropic, Google Gemini, AI21 Labs, and AssemblyAI, then tracks tokens, costs, latency, and error rates in a single view. By pairing gateway-based logging with an OpenTelemetry tracing SDK, it lets engineers inspect entire agent workflows, from high-level tasks down to individual model calls.
Key Features:
Unified LLM gateway: Route requests through one base URL while still choosing models across multiple AI providers and tools.
Token, cost, and latency analytics: Dashboard views show token usage, per-request cost, latency distributions, and error rates across all calls.
Tracing SDK with decorators: OpenTelemetry-based SDK for Python and JavaScript uses decorators such as @workflow and @task to capture end-to-end traces, auto-attaching LLM calls.
Rich attribution metadata: Attributes like customer_identifier, trace_group_identifier, and custom metadata help teams slice metrics by user, project, experiment, or environment.
Flexible logging modes: Teams can either proxy traffic through the gateway by switching the base URL or log requests asynchronously via a dedicated logging endpoint.
Pros
Strong LLM observability: Fine-grained analytics make it much easier to understand where tokens, time, and errors are going.
Quick integration paths: Many stacks only need a base URL change or a few decorators to start emitting traces.
Provider flexibility: Support for several model vendors and speech-to-text APIs suits teams that like to experiment.
Agent-friendly tracing model: Concepts such as workflows, tasks, agents, and tools line up well with modern agent architectures.
Cons
Requires routing changes: Applications must adopt the gateway or SDK, which may feel heavy for very simple prototypes.
Data governance questions: Security teams will want to review how prompts and outputs are stored and who can access logs.
Pricing transparency: Public materials do not clearly show per-plan prices, which complicates early budgeting.
Who is Using Respan?
AI product teams: Monitoring production features that rely on GPT-style models and speech-to-text services across apps and services.
Data and platform engineers: Owning shared AI infrastructure, centralizing provider access, and wiring traces into existing observability stacks.
ML and prompt engineers: Studying traces and analytics to refine prompts, select models, and debug tricky agent behavior.
Startups and agencies: Running multiple client projects while tracking costs and performance per customer or project.
Uncommon Use Cases: Academic labs experimenting with multi-model research agents, and internal tools teams adding tracing to lightweight automation scripts.
Pricing:
Pro: $0 per month. Includes full platform access, 100k logs, 1k scores, 5 datasets, 2 evaluators, and 5 prompts.
Team: $249 per month. Includes everything in Pro, plus unlimited datasets, unlimited evaluators, unlimited prompts, a private Slack channel, and a SOC 2 report.
Enterprise: Custom pricing. Includes everything in Team, plus custom packages, volume discounts, custom SLAs, a dedicated support engineer, and HIPAA BAA.
Disclaimer: Please note that pricing information may not be up to date. For the most accurate and current pricing details, refer to the official Respan website.
What Makes Respan Unique?
Respan brings together three pieces that are often separate: a multi-provider LLM gateway, detailed token-and-cost analytics, and an OpenTelemetry-based tracing SDK tuned specifically for LLM workflows. It understands prompts, models, workflows, and end users as first-class objects, not just raw HTTP calls. The optional Docs MCP integration for coding assistants is a clever touch, letting developers query Respan’s own documentation from within their editor while they wire things up.
How We Rated It:
Accuracy and Reliability: 4.7/5
Ease of Use: 4.2/5
Functionality and Features: 4.6/5
Performance and Speed: 4.5/5
Customization and Flexibility: 4.4/5
Data Privacy and Security: 4.3/5
Support and Resources: 4.0/5
Cost-Efficiency: 4.2/5
Integration Capabilities: 4.8/5
Overall Score: 4.4/5
Focused LLM Observability That Scales With Your Stack:
Respan gives AI-focused teams a practical way to bring order to increasingly complex LLM systems. By combining a multi-provider gateway with tailored analytics and tracing, it helps engineers see exactly how models behave in production, which users or tenants are driving cost, and where workflows slow down or fail. For anyone running serious GPT-style features or agents in production, it offers a thoughtful set of controls and insights that standard logging tools tend to miss.