We may earn compensation from some listings on this page. Learn More
We may earn compensation from some listings on this page. Learn More
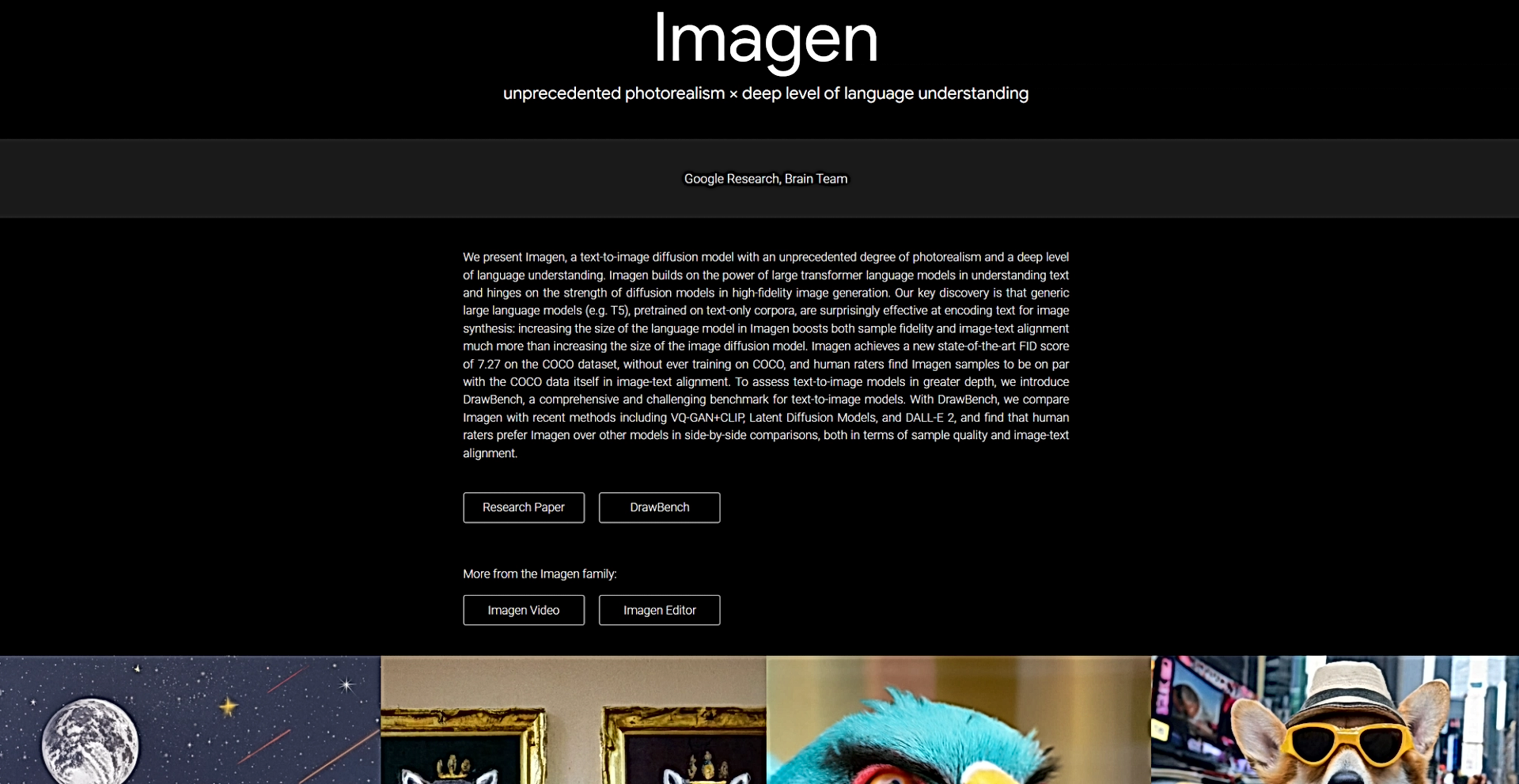
Revolutionizes photorealism in AI-generated images with deep language understanding.
AI Categories: text to image, design generators, marketing
Imagen stands out as a groundbreaking development by Google Research's Brain Team in the ever-evolving sphere of artificial intelligence. This text-to-image diffusion model is revolutionizing the way we think about and interact with AI-generated imagery, boasting an unprecedented degree of photorealism combined with a deep level of language understanding. At its core, Imagen leverages the power of large transformer language models to interpret text inputs, which it then translates into high-fidelity images using advanced diffusion models. This unique combination not only enables the creation of stunningly realistic images from textual descriptions but also pushes the boundaries of AI's creative capabilities.
What sets Imagen apart is its unparalleled ability to generate photorealistic images that are intricately aligned with textual descriptions, thanks to its sophisticated use of large transformer language models and diffusion models. This not only represents a significant leap forward in text-to-image technology but also opens up new possibilities for creative expression and practical applications across various fields.
While direct access to Imagen might be limited, Google Research provides extensive documentation and research papers detailing the technology and methodologies behind Imagen, offering valuable insights for those interested in understanding or developing similar technologies.
Imagen emerges as a pioneering force in the AI landscape, offering an unmatched capability to transform textual descriptions into photorealistic images. Its profound understanding of language, coupled with the ability to produce high-fidelity visuals, positions Imagen as an essential tool for professionals across various industries seeking to leverage AI for creative and practical applications. While access to Imagen remains limited, its technological advancements and potential applications continue to inspire and pave the way for future developments in the field of artificial intelligence.
Featured AI Tools
AI Influencer Creation Platform, pioneers the digital content space by allowing users to effortlessly craft and manage AI-driven virtual personas.
AI Forms for Feedback, Surveys and User Research
Join 200,000 professionals adopting AI tools for work
Did you find this content helpful?
Related Categories
Imagen alternatives
Unlock digital artistry: AI transforms text into stunning visuals, seamlessly via Discord.
Deep learning text-to-image model.
Unleash your creativity with an AI that turns words into visual art instantly.
Transform text into stunning visuals effortlessly with AI-powered creativity.
Harness AI for efficient, community-driven image and text generation.
Infinite image generation powered by AI
Transform text into stunning images or videos with AI-driven creativity.
AI-powered search engine indexes 50+ stock image websites









