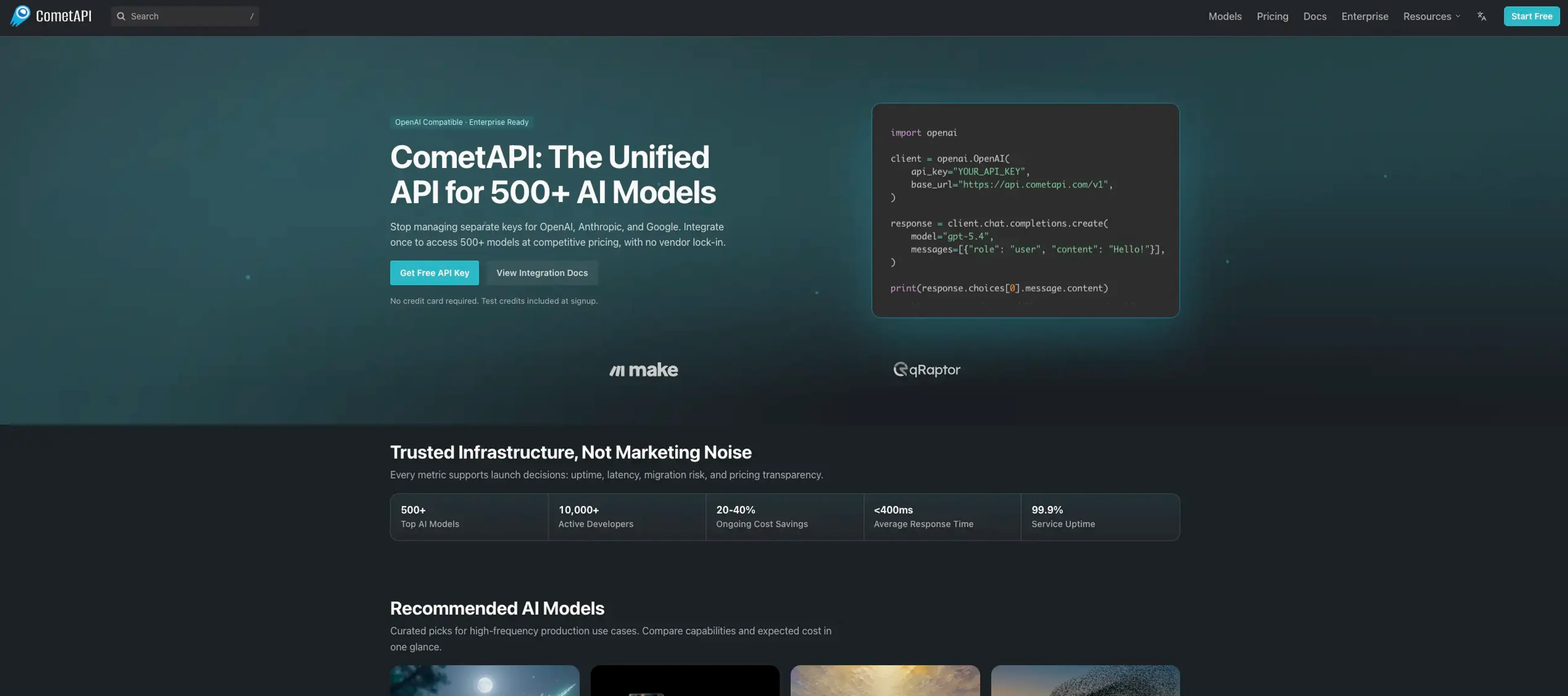
CometAPI is a unified API layer that brings together more than 500 AI models from providers such as OpenAI, Anthropic, Google, DeepSeek, xAI, and others. Instead of juggling separate keys and slightly different SDKs, developers can point an OpenAI-compatible client at CometAPI, choose a model name, and gain immediate access to text, image, video, music, and voice capabilities. The platform focuses on production use, with transparent pricing, latency and uptime metrics, and controls that reduce vendor lock in and billing chaos.
Key Features:
Unified, OpenAI-compatible API: One credential and endpoint for hundreds of models across major vendors, using familiar OpenAI-style requests.
Multi-modal model catalog: Support for chat, reasoning, coding, image, video, and audio models, including families like GPT‑5.x, Claude Opus, Gemini 3.x, Grok, and Sora 2.
Transparent, discounted pricing: Per-token or per-second rates listed per model, typically around 20 percent below official provider prices, with no hidden platform fees.
Usage analytics and cost control: Real-time dashboard showing spend, latency, and call volume, plus budget alerts to prevent surprise bills.
Production-focused reliability and privacy: Targets of 99.9 percent service availability, sub-400ms average latency, encrypted transport, and a policy of not storing prompts or responses.
Pros
Meaningful cost reduction: Discounted rates across popular models can cut AI API spend by roughly 20–40 percent.
Faster experimentation: Teams swap models in a single line of code and compare responses quickly in the playground.
Lower vendor risk: If one provider changes pricing or has issues, traffic can be redirected to alternatives with minimal refactoring.
Developer-friendly experience: Clear docs, SDKs, Postman collections, and example projects help move from prototype to production quickly.
Cons
Additional dependency: CometAPI becomes another critical service in the stack, which some risk-averse teams may question.
Provider features may lag: Very new or niche endpoints from underlying vendors might not appear in the catalog immediately.
Model complexity remains: A single API does not remove the need to understand model behaviour, token costs, and prompt design.
Who is Using CometAPI?
SaaS and App Developers: Adding chat assistants, AI search, and content features without tying products to a single provider.
AI Agencies and Consultancies: Centralising client workloads and billing while choosing the best model per project.
Enterprise Digital and IT Teams: Governing AI usage across departments with shared dashboards, budgets, and model policies.
Automation Builders: Powering n8n, Make, and custom workflow engines with different models for reasoning, images, and video.
Researchers and Prompt Engineers: Benchmarking prompts across many models quickly using one playground and API key.
Uncommon Use Cases: Used by hackathon organisers to standardise access for participants; adopted by indie game studios to prototype characters, dialogue, and assets across text and image models.
Pricing:
Free Credits: Free trial credits included; no credit card required, no monthly fee, no minimum spend, and unused credits roll over indefinitely.
Pay-As-You-Go: CometAPI uses credit-based, per-use billing with no subscription. Text models are billed per token, image models per image or token, video models per second, and audio models per clip or token.
Chat & Text Models: Starts at $0.48 per 1M tokens for MiniMax-M3; common models shown include Claude Opus 4.8 at $4 per 1M tokens, GPT 5.5 at $4 per 1M tokens, and GPT 5.5 Pro at $24 per 1M tokens.
Image Models: Starts at $0.008 per image for FLUX 2 MAX; other listed options include Nano Banana 2 at $0.40 per 1M tokens and Black Forest Labs/FLUX 2 PRO at $0.06 per image.
Video Models: Starts at $0.028 per second for Vidu Q3 Turbo; other listed options include Doubao-Seedance-2-0 at $0.063 per second, Veo 3.1 Fast at $0.08 per second, and Veo 3.1 at $0.32 per second.
Audio Models: Starts at $0.006608 per clip for Kling TTS; other listed options include GPT-4o Transcribe at $2 per 1M tokens, gpt-audio-1.5 at $2 per 1M tokens, and TTS at $12 per 1M tokens.
Enterprise: Custom pricing with volume discounts, dedicated servers, custom models, staff training and integration, unlimited RPM and TPM, extended data storage, and dedicated support.
Disclaimer: Please note that pricing information may not be up to date. For the most accurate and current pricing details, refer to the official CometAPI website.
What Makes CometAPI Unique?
CometAPI stands out by pairing a vendor-agnostic, OpenAI-style API surface with always-on discounts and production-grade monitoring. Instead of simply proxying calls, it exposes clear, line-item pricing, negotiates lower rates, and ships tools for latency tracking, budget controls, and quick A/B testing across models. That blend of cost control, flexibility across providers, and visible reliability makes it feel more like core infrastructure than another experimental dev toy.
How We Rated It:
Accuracy and Reliability: 4.7/5
Ease of Use: 4.6/5
Functionality and Features: 4.8/5
Performance and Speed: 4.8/5
Customization and Flexibility: 4.5/5
Data Privacy and Security: 4.6/5
Support and Resources: 4.5/5
Cost-Efficiency: 4.9/5
Integration Capabilities: 4.7/5
Overall Score: 4.7/5
CometAPI For Serious Multi Model Builders:
For organisations rolling out AI features across several providers, CometAPI offers a single, OpenAI-style API with clear pricing, live metrics, and real cost savings. It suits teams that want to keep their options open, trial new models quickly, and still satisfy finance and security stakeholders through one controlled gateway. Anyone tired of juggling provider keys, rate limits, and slightly different SDKs will find this a cool way to keep experimentation high while admin work stays low.